

 |
Como mostramos diversas aplicações de Inteligência Artificial para Reconhecimento de Imagens e também algumas das principais técnicas utilizadas, neste artigo aprofundamos no desafio relacionado à Segurança do Trabalho. Para ilustrar, vamos pegar um problema clássico nos locais de obras da construção civil: a identificação de capacetes de segurança. Esse problema é baseado na necessidade de garantir que os trabalhadores estejam sempre utilizando os equipamentos de segurança quando estão no ambiente das obras, neste caso específico, o capacete de segurança.
Para construir uma solução, antes é importante definir a abordagem utilizada, levando em conta Qual tecnologia de Reconhecimento de Imagens utilizar na nuvem. Pegando como exemplo as tecnologias da AWS, uma alternativa rápida para chegar a um primeiro resultado e que exige menos desenvolvimento é o Amazon Rekognition. Utilizando chamadas de API para o serviço, ele classifica os objetos na cena e retorna a posição desses elementos em formato json, que são utilizados para desenhar os retângulos verdes que indicam o local que o serviço encontrou o capacete de segurança na imagem.

Porém, se executarmos o Amazon Rekognition diretamente pelo console no modo de detecção de objetos, o resultado poderá ser parecido com a imagem abaixo:
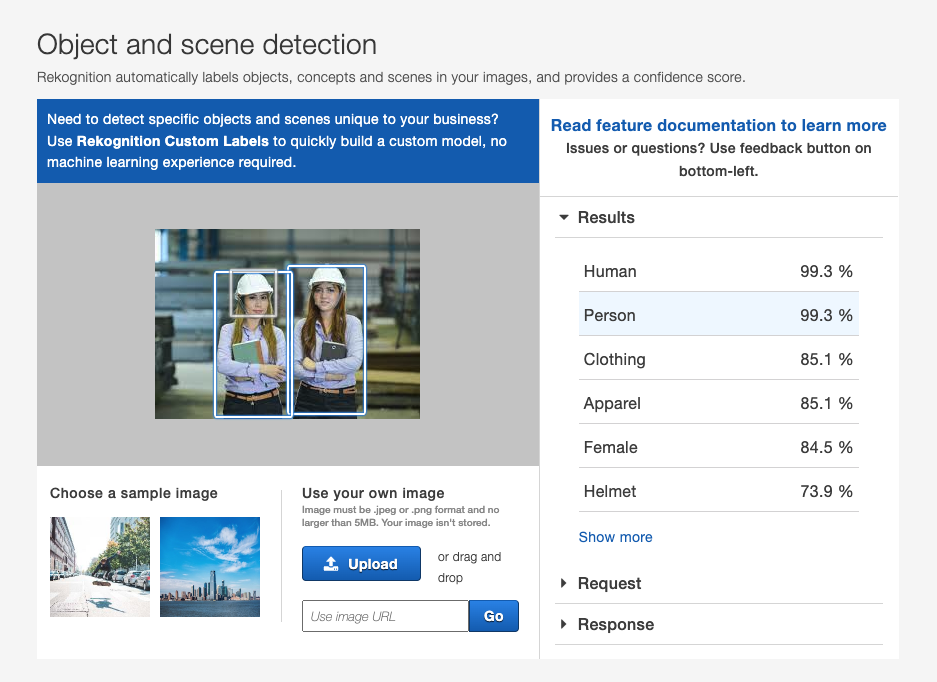
Perceba que nesse modo os objetos encontrados na imagem são apresentados com a percentagem de confiança de cada um e sua posição. Nessa imagem, foi identificado apenas um capacete de segurança (Hardhat), com 73% de confiança, onde claramente são dois. Podemos melhorar o resultado do Amazon Rekognition utilizando o modo de Rótulos Personalizados, que permite incluirmos nossos próprios dados de treinamento, sinalizando na imagem o local dos objetos que estamos interessados, e o próprio serviço realiza um treino específico para esses dados personalizados. De toda forma, essa abordagem mantém o modelo padrão da AWS, sem possibilidade de personalizar o modelo.
Utilizando as tecnologias da AWS, para implementar um modelo personalizado para este exemplo, podemos utilizar o Amazon SageMaker, que é um serviço gerenciado para a criação, treinamento e implantação de modelos de Machine Learning. Neste caso, uma Rede Neural foi treinada utilizando o dataset público disponibilizado no artigo Automatic detection of hardhats worn by construction personnel: A deep learning approach and benchmark dataset, cujos autores realizam um benchmark de alguns modelos de Deep Learning para tratar o problema de detecção de capacetes de segurança. O dataset contém imagem de diversas pessoas, com e sem capacete, com 5 classes para a predição: capacetes de segurança nas cores vermelho, branco, azul, amarelo e sem capacete de segurança. Os resultados obtidos podem ser vistos abaixo:

Nesta imagem, que o Amazon Rekognition não identificou os dois capacetes de segurança, o modelo treinado respondeu com 99,3% e 99,9% de confiança a localização dos capacetes das duas mulheres na foto.
Em imagens onde o objeto a ser detectado está situado frontalmente e sem a presença aparente de movimento, o modelo performa muito bem, como podemos ver também nas imagens abaixo:
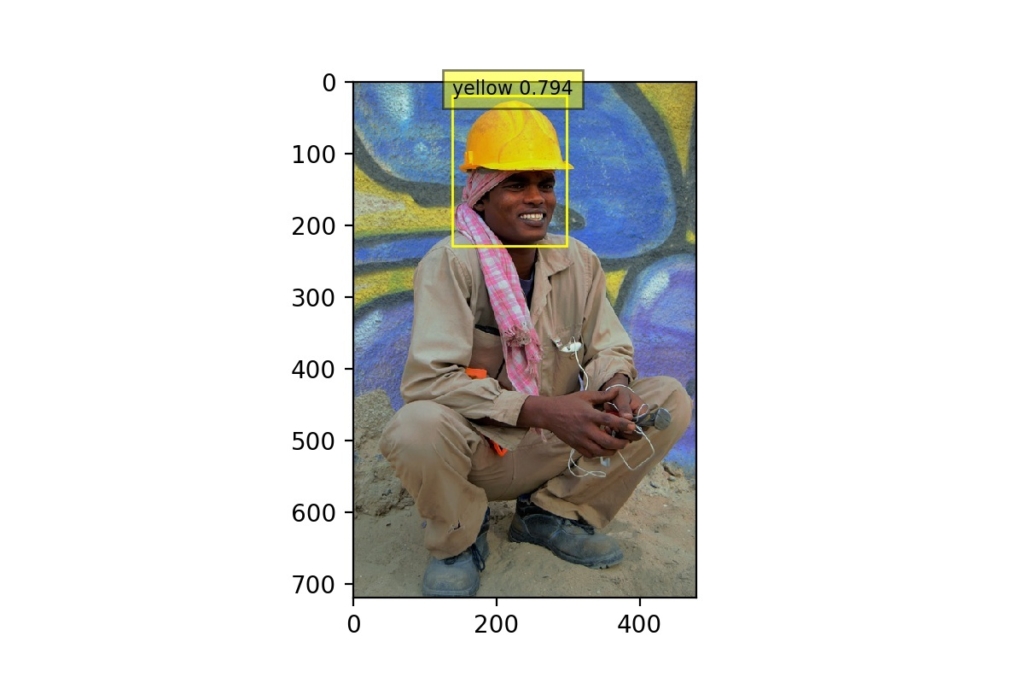
Nesse caso, a identificação dos capacetes amarelos ocorreu com 79,4% de confiança.
O modelo treinando também acerta com probabilidade de confiança elevado em ambientes onde o capacete de segurança é branco e existe pouco contraste na imagem, muita claridade, ou fundo em tons de cinza. Repare na primeira imagem abaixo que o fundo todo está em tons de cinza e a segunda imagem contém outros objetos brancos (ou com tom próximo ao branco), como a camisa de um dos homens refletida pela luz e o carro no fundo.


Testar o modelo em ambientes mais dinâmicos é um dos desafios de aplicações desse tipo. Detectar vários objetos em uma imagem é mais custoso computacionalmente pelo fato de existirem mais possíveis candidatos a detecção.
Ambas as imagens abaixo apresentam ambientes onde existem homens sem capacete de segurança. Nas imagens, none significa que uma cabeça foi identificada sem capacete. Repare a disposição dos homens nas duas imagens. Eles estão de lado, de costas e alguns de frente. O modelo deve conseguir interpretar os capacetes de segurança (ou a ausência deles) em diferentes ângulos, com diferentes posições, mesmo com confiança mais baixa, como foi o caso na primeira imagem, onde o homem destacado a direita teve seu capacete detectado com confiança de 69,3%, bem inferior aos demais que ultrapassaram os 90% de confiança.
Ainda falando em taxa confiança, repare as imagens abaixo. Essas imagens são em ambientes dinâmicos, com sobreposição e diversos objetos em cena.
Em situações como essas, um dos principais parâmetros utilizados nesses tipos de análises é o threshold. Esse parâmetro simboliza a tava mínima de percentual de confiança que estamos dispostos a aceitar para que a predição possa ser considerada. Por exemplo, se o threshold for de 70%, isso indica que predições com taxa de confiança inferior a 70% serão ignoradas.
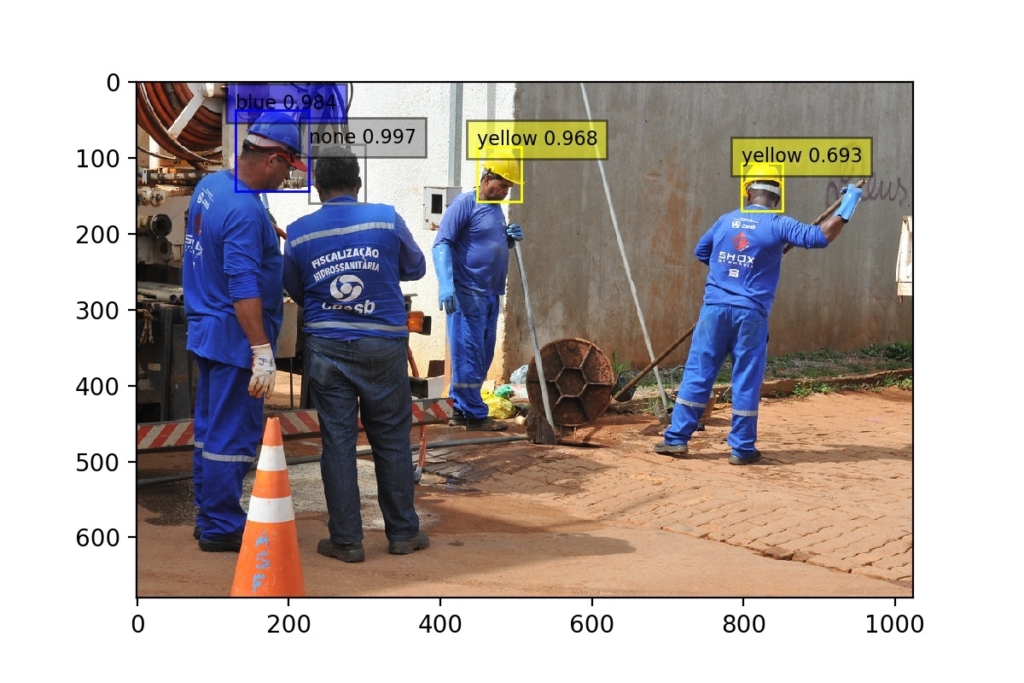
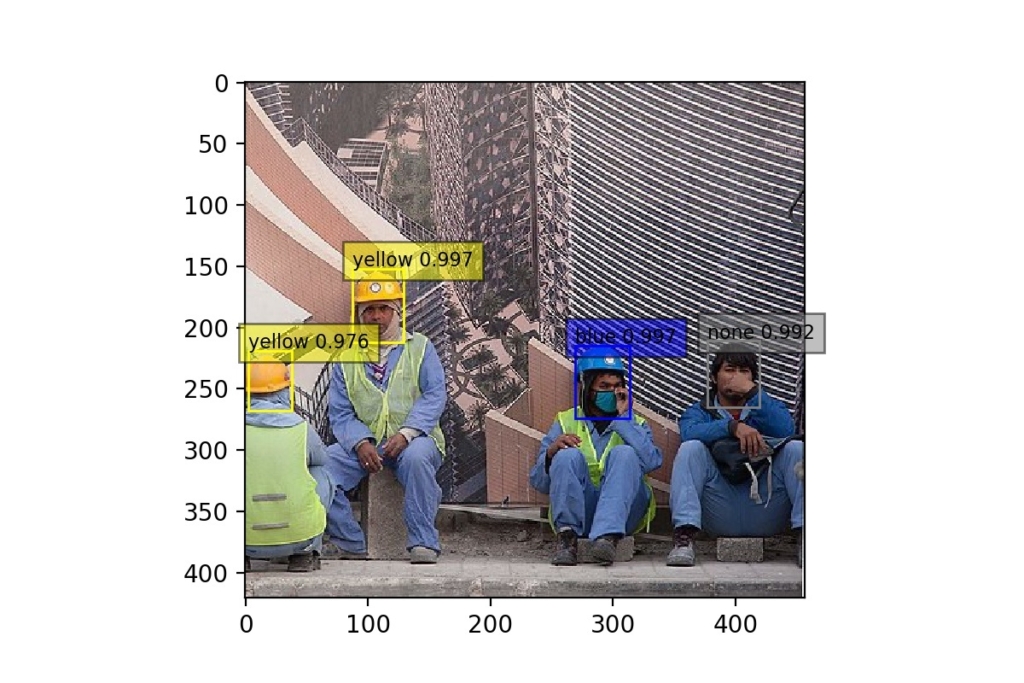
Ambas as imagens apresentadas acima apresentam alguns casos em que a taxa foi bem inferior a isso (veja o bombeiro na primeira imagem, próximo à margem esquerda, que obteve taxa de confiança de apenas 44,5%), o que indica que se tivéssemos configurado o threshold em 70%, perderíamos algumas predições.
Como podemos ver, existem diversos cenários e abordagens para um mesmo desafio. Ao planejar a solução, é sempre importante entender de maneira clara os objetivos para definir a melhor estratégia e selecionar as ferramentas adequadas.
Além disso, testar o modelo com diversos, ângulos, rotações e posições é importantíssimo para que o modelo consiga generalizar suficientemente bem as inúmeras situações que podem ocorrer em um ambiente real. Um bom conjunto de dados de treinamento é peça chave para possibilitar a generalização.

- EMR Serverless (Review) - 9 de junho de 2022
- Visão Geral do Pilar de Segurança para Data & Analytics - 1 de março de 2022
- Visão Geral do Pilar de Excelência Operacional para Data & Analytics - 16 de fevereiro de 2022
Entre em Contato
Para entender como aplicar Inteligência Artificial para o reconhecimento de imagens em seu negócio, entre em contato com nossos especialistas.