

 |
No dia 02 de Junho de 2022 recebemos a feliz surpresa de Swami Sivasubramanian, o VP, Database, Analytics and ML da AWS, anunciando disponibilidade geral do EMR Serverless. O que era disponível para teste apenas para algumas contas selecionadas agora está disponível para uso geral.
O anúncio mais importante para Data & Analytics desde o último re:Invent, trouxe o esclarecimento para público geral de diversas dúvidas que pairavam sobre o EMR Serverless. Seria ele mais um AWS Glue? Vai ficar mais caro que o EMR EC2 ou o EMR EKS? Como desenvolveremos de modo produtivo nesse novo ambiente?

Vantagens do EMR Serverless
A principal vantagem é: ele é Serverless. Embora isso possa parecer óbvio para os que já trabalham em ambiente Serverless por algum tempo, existem muitas pessoas que duvidam um pouco a efetividade dos serviços Serverless.
Para usar o EMR normal com efetividade, teríamos que controlar aspectos de ligar e desligar cluster, auto-scaling (sendo bem mais complexo que um autoscaling de aplicação normal), rede, aceitar o tempo entre 10–15 minutos que o cluster demora para ligar no modo transiente ou pagar 24/7, ou minimamente 9/5 para ter o cluster disponível para aceitar jobs rapidamente.
E não esqueça que com EMR Serverless, só pagamos pelo que usamos, o que já é uma baita vantagem.
Application → Cluster
A principal vantagem é a praticidade de criar apenas 2 recursos: Application e Job. O Application é o equivalente ao cluster, nele configuramos apenas as informações relativas a 1 Worker, quantidade de vCPU e memória, os limites de quanto aceitamos permitir que o cluster escale, ou seja, máxima quantidade de vCPU e memória, informações sobre o comportamento do cluster de inicialização automática quando um job for submetido (você vai querer deixar isso marcado) e também um tempo para “pausar” a application por inatividade.

Além disso, também as configurações de rede são definidas, onde a novidade aqui é não precisar usar sua VPC, tendo um cluster sem acesso a sua rede. Caso precise acessar um banco, poderia configurar a VPC, desde que as subnets sejam privadas.

Só nessa breve descrição, algumas dores dos antigos usuários de EMR foram solucionadas:
- Pausar o Cluster para parar de pagar quando não precisamos;
- Auto Scaling semi-automático;
- Submeter um job com cluster desligado e cluster ligar e executar o job automaticamente;
- Não precisa configurar rede caso use apenas dados do Amazon S3.
Apenas com essas configurações teremos um application criado:

Usabilidade
Para usar de fato, precisamos submeter um job. Esse processo é simular a submissão de jobs em um cluster de EMR padrão, então, quem tiver familiaridade com esse processo não deve ter muitas dificuldades em executar seus primeiros jobs.
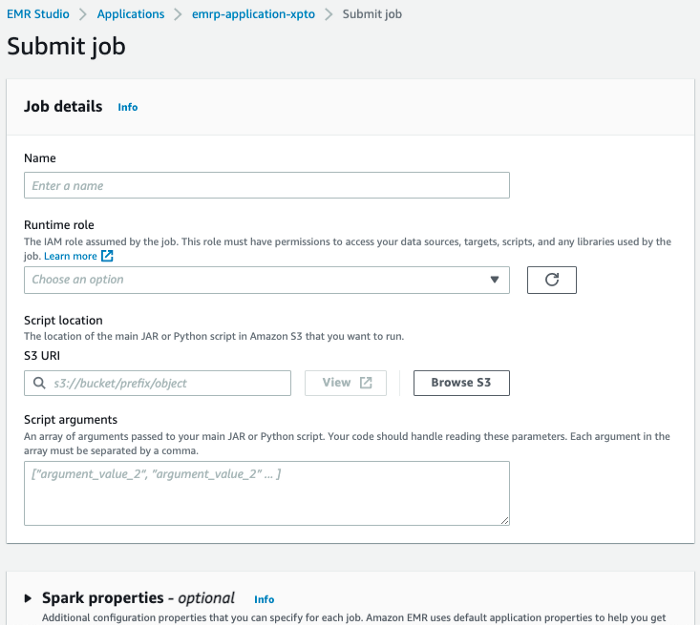
A principal diferença, que ao meu ver é muito conveniente para o ponto de vista de segurança, é a individualização das permissões, no campo Runtime Role. Com isso, cada Job pode ter uma permissão individual, com acesso somente aos recursos necessários.
Ou seja:
- job 1: lê a tabela A e escreve na B;
- job 2: lê as tabelas B e C e escreve na D.
- Na criação da RuntimeRole:
- runtime-role-job1: damos, permissão de leitura da tabela A e escrita na tabela B;
- runtime-role-job2: damos, permissão de leitura das tabelas B e C e escrita na tabela D.
Você pode estar se perguntando o que isso difere do cluster de EMR normal, e é uma pergunta válida, dado a simplicidade do que acabo de descrever. Entretanto, até então, a permissão era do cluster e não do job, ou seja, para conseguir rodar esses dois jobs no mesmo cluster, o cluster deveria ter a permissão runtime-role-job1 e runtime-role-job2 somadas, desrespeitando o básico de privilégio mínimo, por exemplo, o job 2 teria acesso de escrita na tabela B, quando só precisaria de permissão de leitura.
Bugs e Possibilidades de Melhoria
Bug de Rede
Logo na primeira application que criei, notei um bug de rede que não sei explicar ainda o motivo, veja esse print:

Estou escrevendo esse artigo 3 dias depois da submissão desses Jobs da imagem. Até agora eles estão em estado Pending por problemas de VPC. Isso não seria um problema normalmente, bastaria eu ajustar a configuração e subir de novo, mas o que me deixou mais incomodado foi a inexistências de logs para me explicar o que aconteceu e a impossibilidade de deletar a estrutura. Estou literalmente em deadlock nessa aplicação, veja:


Resumo da ópera: eu não consigo deletar um job com erro, ele fica eternamente em pending, mas para deletar a application o job não pode estar em pending. Estou a mais de 48h com o job como Pending. Vamos esperar até a AWS corrigir esse problema e enviar os jobs travados para o estado FAILED após um período de inatividade, só assim poderei deletar essa application.
Possibilidades de Melhoria
Além da correção acima, uma coisa que senti falta é a possibilidade de integração com notebooks para desenvolvimento. Quem quiser ter um notebook com spark para desenvolver na AWS, o jeito continua sendo o arcaico “subir um cluster e todo mundo conecta nele”.
Comparativo de Preço
Fiz algumas comparações de preço, simulando um cluster com 10 máquinas com 4vCPUs e 32GB de memória:

Repare que o custo é quase 3 vezes maior por hora, as apenas essa imagem não diz tudo. Existem muitos pontos a considerar, como:
- o tempo que demora para um job executar no EMR Serverless, que é 3 vezes menos do que subir um cluster no EMR EC2;
- o auto scaling automático, minimizando o tempo dos jobs, gerando economia;
- menor custo operacional devido a natureza serverless;
- mais fácil de desenvolver, tecnologia conhecida, melhorando o tempo de desenvolvimento;
- só é cobrado pelo que usar.
Essa análise “burra” de custo nunca nos conta toda a história. É como comparar AWS Lambda com Amazon EC2. O Amazon EC2 é obviamente mais barato, mas o AWS Lambda vence no TCO (Total Cost Ownership), devido a todas as vantagens serveless e ainda por so pagar pelo que usa. Veja mais TCO aqui.
Um gráfico que conta melhor a história seria assim:

Com o gráfico acima conseguimos colocar alguns outros aspectos a se considerar na escolha do serviço. De fato, em alguns cenários que o custo de processamento é o mais relevante, como jobs de altíssima duração — pense em algo que demora 20 horas por dia seguidas para processar — , outras versões do EMR podem fazer bastante sentido, mas em cenário padrão de jobs ocasionais que poucos minutos, ou no máximo algumas dezenas de minutos, parecemos ter mais vantagens que desvantagens escolhendo um serviço serverless.
Por onde começar
Para quem quiser começar a testar o EMR Serverless, a AWS disponibilizou um exemplo no GitHub. Eu utilizei esse exemplo como base para fazer meus testes. Caso tenha interesse em começar e ter uma base, segue o link: Samples de EMR Serveless
Atualizações
EMR Serverless ainda não permite o uso de imagens personalizadas, caso você precise usar alguma lib que não esteja na versão escolhida do EMR Serverless, não é possível instalar — contribuição do Willian “Bill” Rocha.
Conclusão
Embora ainda não atenda 100% das nossas demandas, o EMR Serverless foi o serviço que mais entrega do ponto de vista de computação genérica, quase open source, e controlada por um preço aceitável. O preço, ao meu ver, justifica o uso comparando com EMR EC2 e EMR EKS. Tirando a parte dos notebooks de desenvolvimento, existem pouquíssimos casos específicos em que valha a pena ter um cluster EMR convencional, transformando o EMR Serverless num belo concorrente para Databricks e outros players do mercado de processamento de Dados Spark.
Referências
- Post de lançamento EMR Serverless: https://www.linkedin.com/feed/update/urn:li:activity:6937906708597923840/
- Samples de EMR Serveless: https://github.com/aws-samples/emr-serverless-samples
- TCO and cost optimization: https://aws.amazon.com/blogs/publicsector/tco-cost-optimization-best-practices-for-managing-usage/

- EMR Serverless (Review) - 9 de junho de 2022
- Visão Geral do Pilar de Segurança para Data & Analytics - 1 de março de 2022
- Visão Geral do Pilar de Excelência Operacional para Data & Analytics - 16 de fevereiro de 2022