|
Sempre que pensamos em inovação, em criação de produtos disruptivos, em algum momento esbarramos com nomes como Machine Learning, Inteligência Artificial, Big Data, Internet das coisas (IoT), Blockchain. Esse movimento vem crescendo tanto nos últimos anos que quando uma empresa diz que está utilizando uma destas tecnologias, automaticamente entende-se que estamos de fato falando de uma empresa moderna, indústria 4.0, Data-Driven, entre outros termos. Mas já se perguntou no que é necessário para começar um projeto que usa essas tecnologias? Neste artigo irei focar em como fazer isso para Inteligência Artificial e Machine Learning.
Esse processo de busca dessas tecnologias, parecido com as hypes das redes sociais, levou a um fenômeno engraçado onde empresas querem utilizar te Machine Learning como fim, não como meio. A busca da técnica pela técnica, em geral, não gera valor efetivo para o negócio. Ao começar um projeto dessa forma, existe uma grande chance de estarmos entrando em um vortex que desperdício de recursos sem resultado útil, sem valor. Ai vai a primeira máxima para nossa Jornada em Machine Learning:
1 – Machine Learning não é uma motivação, e sim uma ferramenta
Entendida nossa primeira máxima, qual deveria então ser a motivação para um projeto desse? O Motivador deveria ser um problema de negócio, mas não qualquer problema, um problema que em geral não é resolvido de forma mais fácil, mais barata, e mais otimizada de outra forma.
Sabendo disso, uma pergunta deve surgir na mente do leitor: Como sei então se devo partir para Machine Learning ou tentar outras coisas primeiro?
Ótima pergunta e ótimo momento para entrarmos na nossa segunda máxima, que nada mais é de uma definição quanto ao uso de Machine Learning.
2 – Machine Learning resolve problemas muito complexos para abordagens tradicionais ou onde não existam algoritmos conhecidos para resolvê-los
Para exemplificar a frase acima, pense em um problema de recomendação, os do tipo que empresas como a Netflix enfrenta ao te recomendar uma série, ou um problema de segmentação de clientes de uma corretora de investimentos. Nossa intuição pode nos levar a pensar que, em termos mais simples, poderíamos construir um programa cheio de IF’s e Else’s para olhar o histórico de visualização dos usuários da Netflix e recomendar um filme, ou olhar o histórico de transações financeiras dos clientes para mapear um perfil de investidor.
O grande problema disso é que esse tipo de problema é tão complexo, exige tantas regras, tantas exceções, que é praticamente inviável para qualquer negócio construir uma máquina de regras tão complexa, que suporte alterações conforme o tempo passa e os gostos de séries dos assinantes mudam. A impossibilidade de criar e/ou manter tal máquina de regras nos leva a pensar em modelos estatísticos, ou seja “inteligentes”, que se baseiam nos dados disponíveis e criar um modelo que “entende” os padrões dos dados e nos dizem que existem alguns grupos de clientes que são mais parecidos do que outros, e esses grupo possivelmente seria uma boa classificação para mapear um perfil de investidor. Da mesma forma, um modelo de recomendação de séries nos diz que existe um pessoas com gostos parecidos tendem a gostar de coisas parecidas então se temos dois assinantes parecidos, se um viu uma série e gostou, porque não indicar a mesma série para o segundo assinante?
Já no ponto de vista de problemas onde não existam algoritmos conhecidos para resolvê-los, podemos citar o reconhecimento de padrões em imagens. Empresas do ramo do Agronegócio, por exemplo, têm desafios no ponto de vista de mapear a qualidade de frutas por imagem, contar produção, contar a quantidade de gados em um pasto. Para esse tipo de problema, não existe um algoritmo conhecido. As técnicas de hoje, dado o estado da arte da pesquisa científica, que melhor resolvem esse tipo de problema são as técnicas de Inteligência artificial.
Alguns outros possíveis problemas que são geralmente resolvidos utilizando inteligência artificial são:
- Criação de propagandas personalizadas
- Análise de comportamento de clientes
- Otimização de rotas de transportadoras
- Cálculo de Score de crédito
- Detecção de fraudes financeiras
- Previsão para operar na bolsa de valores
- Business Understanding, onde nos aprofundamos no problema de negócio a ser resolvido.
- Data understanding, que é o processo onde avaliamos o entendimento do negócio e do problema com os dados disponíveis.
- Data Preparation, que é o momento de preparar os dados para o formato que um modelo espera como entrada
- Modeling, onde os modelos são desenvolvidos. Perceba que um loop nesse processo de Data Preparation e Modeling é normal para adequar os dados de entrada para o modelo as modificação no decorrer do desenvolvimento do modelo.
- Evaluation, onde depois de validar que o modelo está performando de modo satisfatório, baseado em métricas.
- Deployment, onde o modelo validado é colocado em produção
- A figura acima mostra a existência de diversos loops dentro do diagrama do CRISP-DM para nos orientar que esse processo é contínuo. Os dados mudam, o comportamento das pessoas muda, os produtos mudam, isso leva a necessidade constante de atualização dos modelos, novo entendimento do negócio, entendimento dos dados, criação, avaliação e publicação de novos modelos. O modelo deve ser algo vivo, monitorável, e quando ele degrada, devemos ser capaz de melhorá-lo com os novos dados que foram gerados no seu período de vida útil. Boa frase para nossa terça máxima:
- Alcançar maturidade nesse processo é um desafio para qualquer organização. Segundo o modelo de pilares de maturidade utilizado pela AWS, chegar a esse nível é estar no nível 4 de 5 na jornada de Inteligência Artificial (ou seja, estar na maturidade 4 de Otimização), onde:
-
- Explicação: Explorando o que IA pode realizar pela empresa. Nesse momento, a organização ainda não possui um modelo ou solução de IA em produção
- Experimentação: Experimentando soluções com provas de conceitos e projetos pilotos. A empresa ainda está tentando utilizar soluções de IA em produção de formas limitadas.
- Formalização: Evolução de uma prova de conceito ou projeto piloto para uma solução de Inteligência Artificial em produção.
- Otimização: Implementando soluções de IA em escala e de maneira otimizada na maneira que a quantidade de modelos de IA aumenta. Nesse momento, a empresa está se aproximando de uma fábrica de implementação de modelos de IA.
- Transformação: Transformação da organização através da Inteligência Artificial. A empresa utiliza IA na operação e em áreas críticas do negócio.
- Entendimento do problema
- Levantamento de soluções disponíveis
- Adquirir dados necessários
- Prova de Conceito (PoC)
- Esteira de MLOps
- Quais os dados necessários para alimentar a solução?
- Mesmo serviços prontos exigem formatos específicos de dados
- Possuo os dados necessários?
- Os dados estão organizados?
- Os dados são consultáveis?
- Preciso gerar ou comprar dados?
- EMR Serverless (Review) - 9 de junho de 2022
- Visão Geral do Pilar de Segurança para Data & Analytics - 1 de março de 2022
- Visão Geral do Pilar de Excelência Operacional para Data & Analytics - 16 de fevereiro de 2022
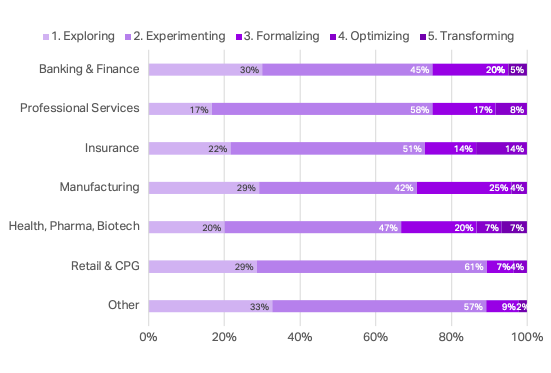
A Jornada de Inteligência Artificial definitivamente não é fácil, envolve todas as áreas da empresa, quando chegamos no pilar número 5, Transformação. São poucas empresas que já conseguiram chegar nesse pilar de maturidade e estão transformando seu segmento de atuação e modo que seus clientes interagem com seus produtos e serviços utilizando Inteligência Artificial. Para ilustrar o desafio de ser uma empresa com maturidade de Transformação, uma pesquisa realizada pela Element AÍ mostrou que tirando o segmento de Seguros, nenhum segmento tem mais de 10% das empresas com nível de maturidade de Transformação, veja o gráfico abaixo:

O desafio da jornada é grande pois envolve 5 grandes dimensões de uma organização:
Estratégia
Plano para atingir o nível desejado de maturidade de IA na empresa
Dados
Os dados necessários para suportar os objetivos de IA da empresa
Tecnologia
Tecnologias, ferramentas e infraestrutura para treinar e entregar modelos de IA
Pessoas
Lideranças e capacitação para entregar as soluções de IA
Governança
Processos e tecnologias para garantir segurança e confiabilidade nas soluções
Passado os aspectos que norteiam a jornada de IA, gostaria de deixar o passo a passo, de como iniciar essa jornada do jeito certo, evitando os vortex de desperdícios de recursos e gerando valor no final da linha.
Para começar, sugiro um passo a passo de ações que devem ser executadas no seu primeiro projeto de Machine Learning, nesta ordem estrita. O passo a passo que sugerirei a seguir deve valer para qualquer tipo de empresa, de qualquer segmento, não importando o seu tamanho, a quantidade de recursos financeiros disponíveis, nem mesmo ao nível de senioridade dos colaboradores envolvidos no projeto. O não cumprimento destes passos para seu primeiro projeto de Machine Learning pode acarretar em um vortex de desperdícios de recursos, que deveríamos querer evitar a todo custo.
Mas o que é o seu primeiro projeto de Machine Learning? É o início de uma nova solução, e mesmo que já existam modelos desenvolvidos dentro da organização, se for começar uma nova solução, este passo a passo deve ser seu guia. O resultado dele será uma Prova de Conceito (PoC) funcionando em produção, onde as próximas etapas de melhoramento do modelo podem seguir o modelo do CRISP-DM sem demais problemas.
Vamos ao passo a passo:
Na primeira etapa, Entendimento do problema, devemos mapear qual é o resultado esperado para solucionar esse problema, o critério de sucesso. Entrar nessa fornada sem isso claro já é um sinal para dar um passo atrás, pois o entendimento disso é mandatório para seguir para as próximas etapas. O critério deve ser condizente com o que esperaríamos para uma PoC, ou seja, nada de critérios como 99,99% de assertividade pois esse tipo de resultado não é possível. Cada tipo de problema tem sua métrica e o que é considerado bom e ruim para o estado da arte, então uma análise deste tipo é necessária. Tendo isso, esse problema pode ser resolvido com programação? Esse problema pode ser resolvido com análise de dados do passado? Esse problema pode ser resolvido com estatística? aqui vale lembrar da nossa segunda máxima. Depois disso, devemos avaliar se é um problema clássico de Machine Learning e qual o estado da arte deste problema, bem como se do ponto de vista de Machine Learning isso é um problema ou vários problemas em cascata.
Perceba a quantidade de combinações possíveis para a primeira etapa. Poderíamos construir algumas combinações que levam a continuar o passo a passo e ir para segunda etapa e outras que levam a abandonar o problema aqui mesmo. Veja um exemplo diagrama que pode te ajudar a tomar a decisão de continuar o passo a passo:
O segundo passo é levantar as soluções disponíveis. Em geral é possível achar bons serviços de Machine Learning para resolver problemas clássicos como transcrição de áudio, detecção de certos tipos de imagem, tradução, análise de sentimento em texto e geração de texto para voz. Em geral esses serviços cobram pelo uso de dados e chamadas de API, logo, se existe um serviço desse tipo que resolva o seu problema e ainda fique dentro do orçamento estimado para aquela solução, use esse serviço. Os modelos que resolvem a maioria desses problemas clássicos são tão complexos e tão caros de desenvolver que fazê-los na maioria das vezes não faz sentido.
Se o seu caso é um modelo que foge desses clássicos, não existe uma solução pronta que resolva esse problema com baixo nível de implementação, estamos falando da necessidade de criação de um modelo do zero, ou seja, ir para o terceiro passo.
O terceiro passo, Adquirir dados necessários, é o processo mais custoso e mais importante de toda essa jornada. O número que em geral utilizamos no mercado é que 80% do esforço necessário para ter bons resultados em modelos de Machine Learning está relacionado com ter bons dados e conseguir utilizá-los. Aqui é um bom ponto para inserir nossa quarta máxima:
4 – Mais vale bons dados e modelos medianos do que excelentes modelos e péssimos dados
Do ponto de vista de dados você precisa de preocupar em responder às seguintes perguntas:
Não é incomum os modelos de Machine Learning precisarem de dados que não possuímos ou dados que possuímos mas não de um jeito suficientemente organizado e limpo para serem utilizados. Aqui entra um processo de Engenharia de Dados e às vezes processo de geração de dados por meio do processo de ground truth e também a compra de dados de fontes terceiras. Existem empresas que vendem dados de alta qualidade e podem suprir lacunas que a organização possa ter em problemas específicos. Mas claro, os dados específicos do negócio a própria organização tem que ter. Uma empresa nova, sem dados, não consegue ter inteligência em cima de dados que não existem. A própria amazon.com guardou dados de vendas de produtos e clientes por anos a fio sem saber o que fazer com eles até conseguirem utilizá-los para alimentar inteligência. A quinta máxima então é:
5 – Os dados são os ativos mais valiosos de uma organização
Tire um tempo para refletir sobre a quinta máxima respondendo a seguinte pergunta: o que aconteceria com a sua organização se você perdesse todos os dados históricos de modo irreversível?
Já tem os dados? Vamos para a Prova de conceito (PoC). Nesse momento nós já chegamos a um nível mais interativo, onde o CRISP-DM começa a fazer sentido para o primeiro projeto de Machine Learning. Neste passo devemos de favor escolher os dados que iremos utilizar, criar o modelo, realizar treinamentos, validar se os dados são suficientemente significativos para o problema que estamos tentando resolver e avaliar nosso resultado.
Perceba que neste momento estamos rodando uma iteração do CRISP-DM, onde precisamos ter um modelo suficientemente bom para passar no critério de avaliação da PoC, ou seja, o critério de sucesso da PoC que estabelecemos lá no primeiro passo. Finalizada a PoC, precisamos colocar esse modelo em produção.
O quinto e último passo do seu primeiro projeto de Machine Learning é colocar esse modelo no ar. Um modelo que funciona apenas no Jupyter notebook ou “na minha máquina”, na verdade não funciona. Existem diversos casos de modelos e são ótimos na teoria e inviáveis para a vida real. Criar a esteira de MLOps nesse momento, que é o nosso quinto passo, nos mostra e ressalta a importância de pensamento DevOps para projetos de Machine Learning já no Dia 0. O que acontece se chegarmos aqui e não conseguirmos colocar o modelo de modo viável em produção? Vortex de desperdício de recursos.
Como queremos evitar o Vortex, precisamos das habilidade de um profissional de Engenharia de Machine Learning para colocar esse modelo em produção e estruturar um pipeline de atualização do modelo de forma ágil, com monitoramento do modelo em produção de modo a conseguir extrair informações deste modelo para melhorar o modelo no futuro nas próximas iterações.
Seguiu todos os passos? Parabéns, você deve ter agora o seu primeiro projeto de Machine Learning em produção, desviou de todas as ciladas que levam aos Vortex e começou muito bem a sua Jornada de Inteligência Artificial e, o mais importante, construiu um caminho sólido para as próximas atualizações do modelo e desenvolveu conhecimento que serão utilizados para os próximos projetos de Machine Learning que certamente colocará no ar.
Espero que essas orientações ajudem você e sua empresa a começar bem sua Jornada de Inteligência Artificial. Se precisar de apoio ao longo desses passos com treinamentos, workshops de evangelização, consultoria de boas práticas de projetos de Dados e Machine Learning na Nuvem, entre em contato que podemos te ajudar.
Bernardo Costa é Cientista de Dados na Solvimm e possui as certificações de AWS SysOps Administrator, AWS Machine Learning - Specialty e GCP Data Engineer Professional Level, além de fazer parte do programa AWS Black Belt de Machine Learning e Inteligência Artificial.Últimos posts por Bernardo Costa (exibir todos)Artigos Relacionados:
Entre em Contato
Para entender como aplicar Inteligência Artificial para o reconhecimento de imagens em seu negócio, entre em contato com nossos especialistas.
[contact-form-7 id=”1630″ title=”Formulário – Blog”]
Isto entendido, podemos passar para segunda parte artigo: Como são estruturados os projetos de Machine Learning?
A metodologia mais utilizada na indústria para projetos desse tipo é o Cross Industry Standard Process for Data Mining (CRISP-DM).
O CRISP-DM tem objetivo de criar um processo iterativo para solucionar problemas de negócio utilizando dados. O CRISP-DM é dividido em 6 fases: